コロナウイルスとWHOのデータ
2020年05月31日 毎日のコロナウイルスの感染者数と死亡数はニュースで見ていたが、ふと気になって今更ながら、WHOの公式サイトを見てみた。
どうも腹落ちしない。何故腹落ちしないのか考えてみた。3つのファクターがあることに気づいた。
- WHOは中国寄りという疑いの目(米国のプロパガンダのせいかも)
- そもそものデータの信憑性(日本の数値の作り方のせいかも)
- データを並べてもランキングは分かるが本質が見えない(分析癖のせいかも)
自分自身が色メガネで見ていたことに気づいた。 そこでジョンズポプキンス大学のサイトを見て、ついでにそのカラクリを見つけた。
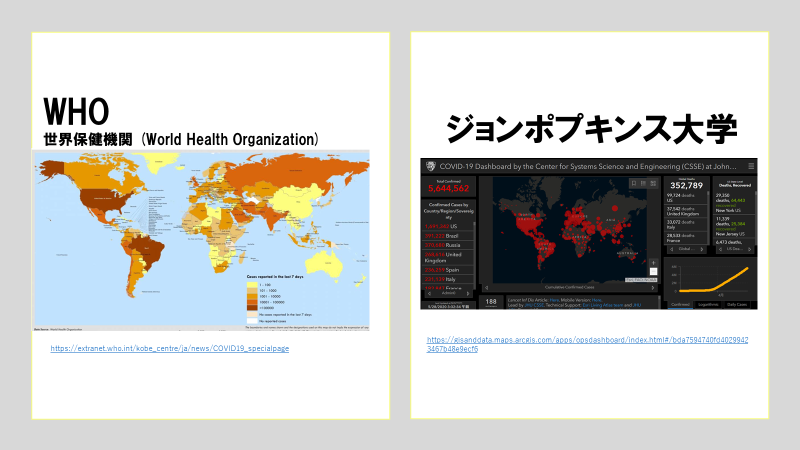
結論1 WHO、JP大学も信憑性は同じ
WHOよりジョンズポプキンス大学のほうが信用できるということにはならなかった。世界中のマスコミが使っているジョンズポプキンス大学のデータはWHOより「早い」「見やすい」のであって、データの信憑性はどちらも変わらないという結論に達した。
結論2 データを見る時に色メガネは禁物
データを読み取るという行為の裏側にはその人の期待値が無意識に存在する。裏側とは潜在的な期待値であり色メガネで見ることにつながってしまう。意識してこの潜在的な意識を排除していく行為をしなければならないと自戒した。
新しい課題 不確実なデータを見る目
人類は情報社会からデジタルデータ社会への移行中であり、ビックデータとAI分析で何でも解決できる、それがデジタルトランスフォーメーション(DX)と思っていた。
しかし、デジタルテクノロジーへの過信は大いなる危険性が伴っている。何しろ精度のよいデータが手に入らないのだから。不確実なデータを使って、真実の姿を見るにはどうしたらよいかという新しい課題が出てきたとに気づいた。
データ分析はアバウト(大雑把)に
そこで私の取ったデータ分析のやり方は、まず目的を明確にして、その目的を達成するために他のデータと結び付けてアバウト(大雑把)に丸めて見るという手法である。
目的は、「そもそも日本の感染者数は正しいのか確かめる」とした。感染者数、死亡者数と世界の国の人口のデータと紐付けて、感染者率(感染者数÷人口)と死亡率(死亡者数÷感染者数)を計算して比べてみた。
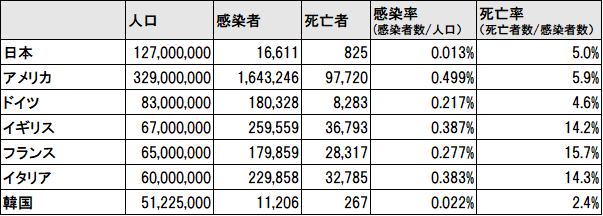
さらにドイツ、イギリス、フランス、イタリアの数値を平均化してEUとしてみた。
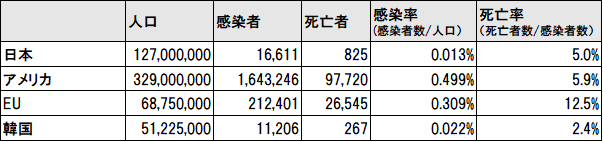
それをグラフにして見て、ぎょっとした。
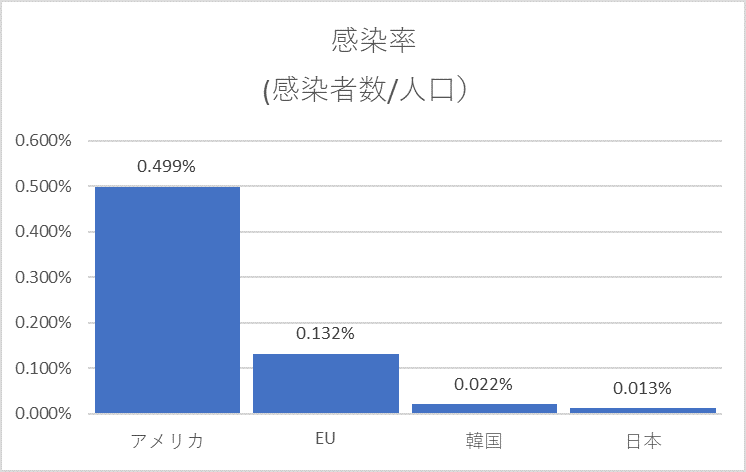
さらに日本を基準にして比較してみた。
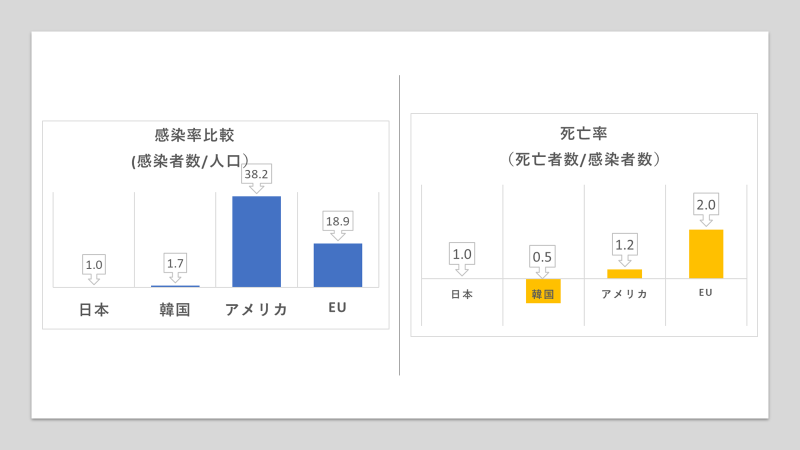
グラフから見えてくる 疑問1 グローバルスタンダード
グラフから類推すると、アジア(日本、韓国)と欧米(米国、EU)と特徴が分かれた。ここから新しい疑問がわく。そもそも同じウイルス(COVID-19)なのか?仮に同じウイルスとすると、次の疑問は欧米人とアジア人の体質(DNA)に違いがあるということになる。人種によって体質(DNA)の違いがあるとすると欧米で開発されたワクチンはアジア人には有効でないことになり、グローバルスタンダードは崩れていく。
グラフから見えてくる 疑問2 米国の数値の異常性
米国の感染率が他の国比べて異常に高いことに気づく。そこから以下のようなことが考えられる。
- 米国は感染率を高くし、危機を煽っている可能性がある。
- グラフにはないがニューヨークがその半数以上を占めている点からすると、そもそも米国という国単位でなく、地域、州単位で見る必要があるのではないか。
- また分母を人口にしてよいのか。検査数を分母したものと比べて見たい気がする。
グラフから見えてくる 疑問3 日本と韓国の相違点
日本と韓国のCOVID-19に違いはない。グラフには反映されていないが周知の事実として検査数の違いがある中で、日本を1にして感染率を見ると、韓国は約2倍、死亡率(死亡者数÷感染者)は約1/2なる。結果ほぼ同じ確率になる。
韓国の対策が正しくて日本の対策が間違っているとは言い切れない。
結論
データを見るためのリテラシーを一人一人が身につけておかないと無意識のうちに権力者とそれに追随するマスコミにいいようにやられてしまう危険が潜んでいる。
AI、DXデータ主導社会への警鐘として捉えることにしたというのが私の結論である。
